PDF) Incorporating representation learning and multihead attention
Descrição

Group event recommendation based on graph multi-head attention network combining explicit and implicit information - ScienceDirect

Build a Transformer in JAX from scratch: how to write and train your own models
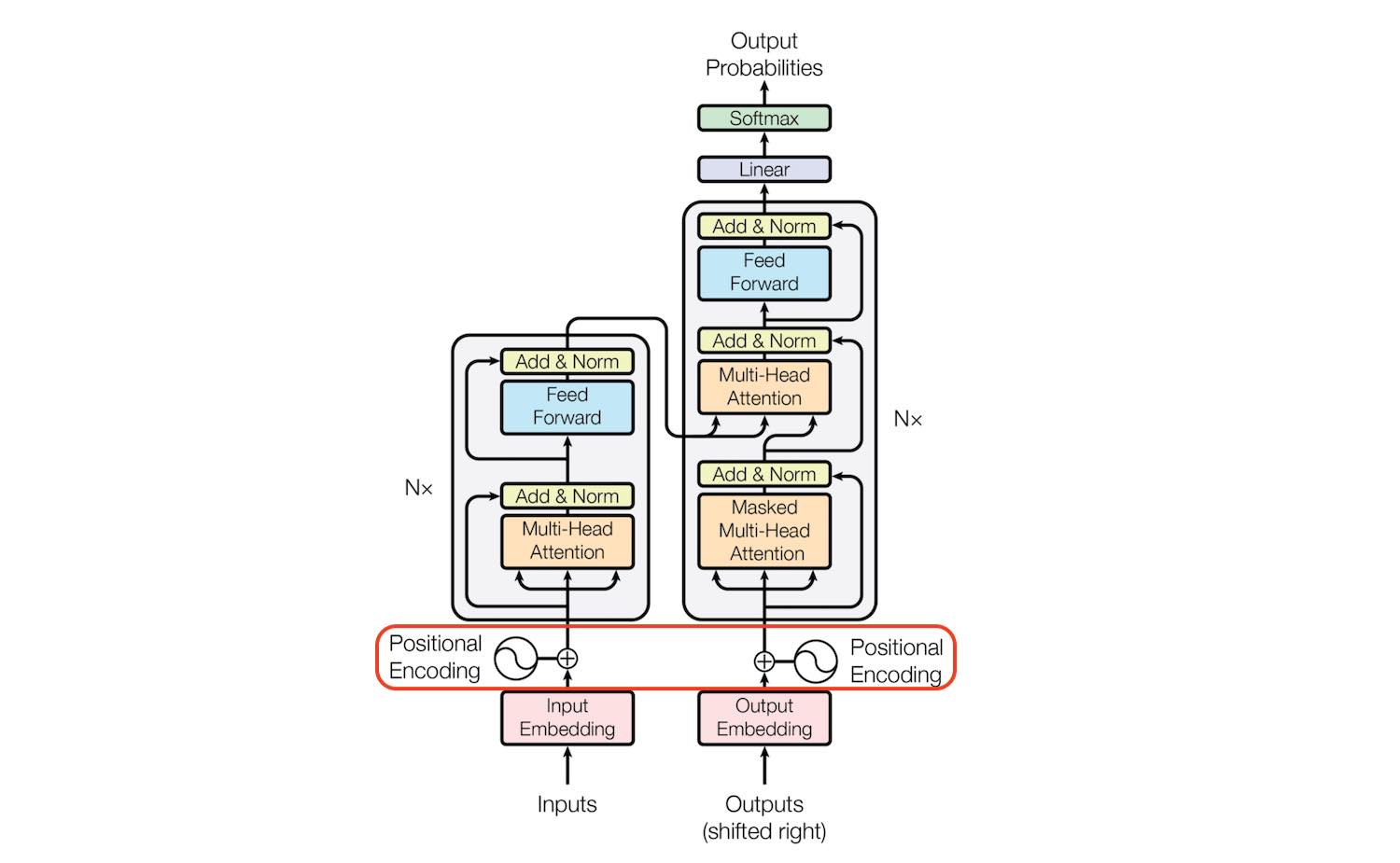
Transformer Architecture: The Positional Encoding - Amirhossein Kazemnejad's Blog
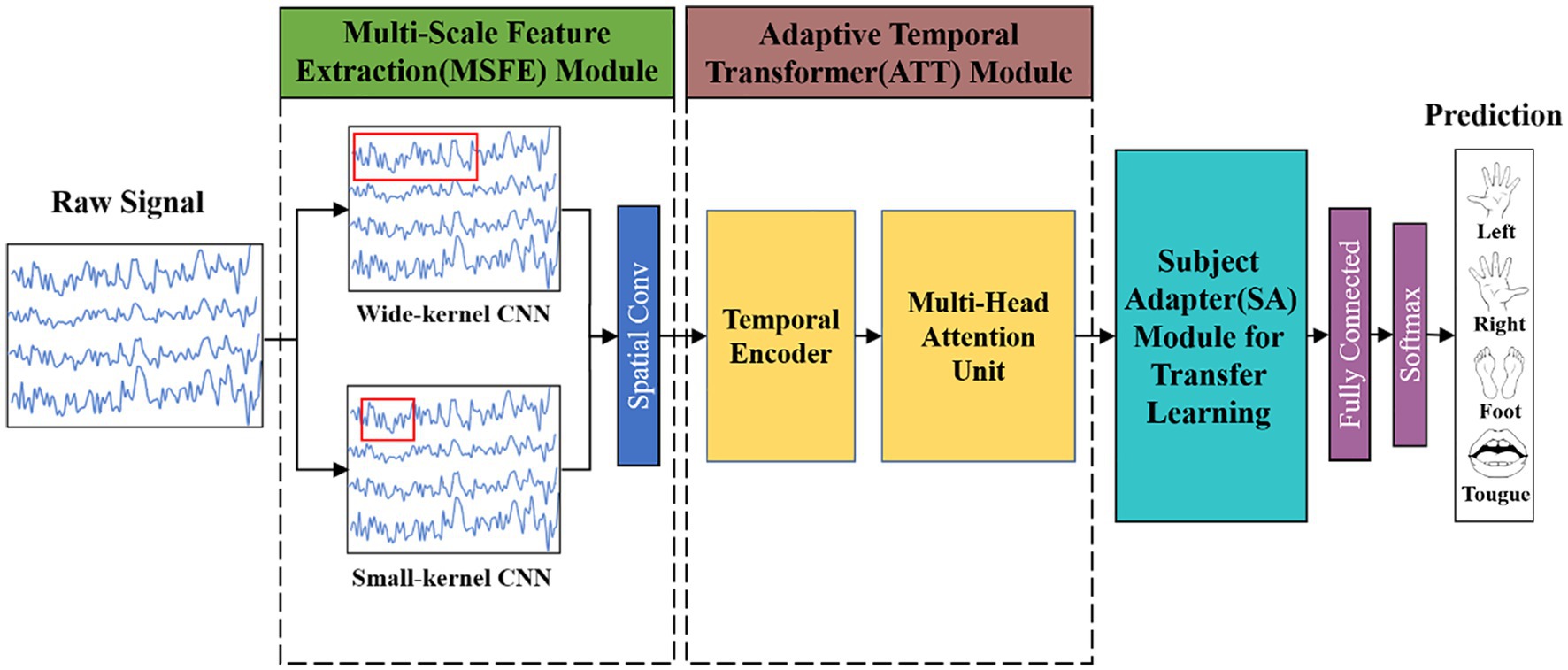
Frontiers MSATNet: multi-scale adaptive transformer network for motor imagery classification

PDF] Informative Language Representation Learning for Massively Multilingual Neural Machine Translation
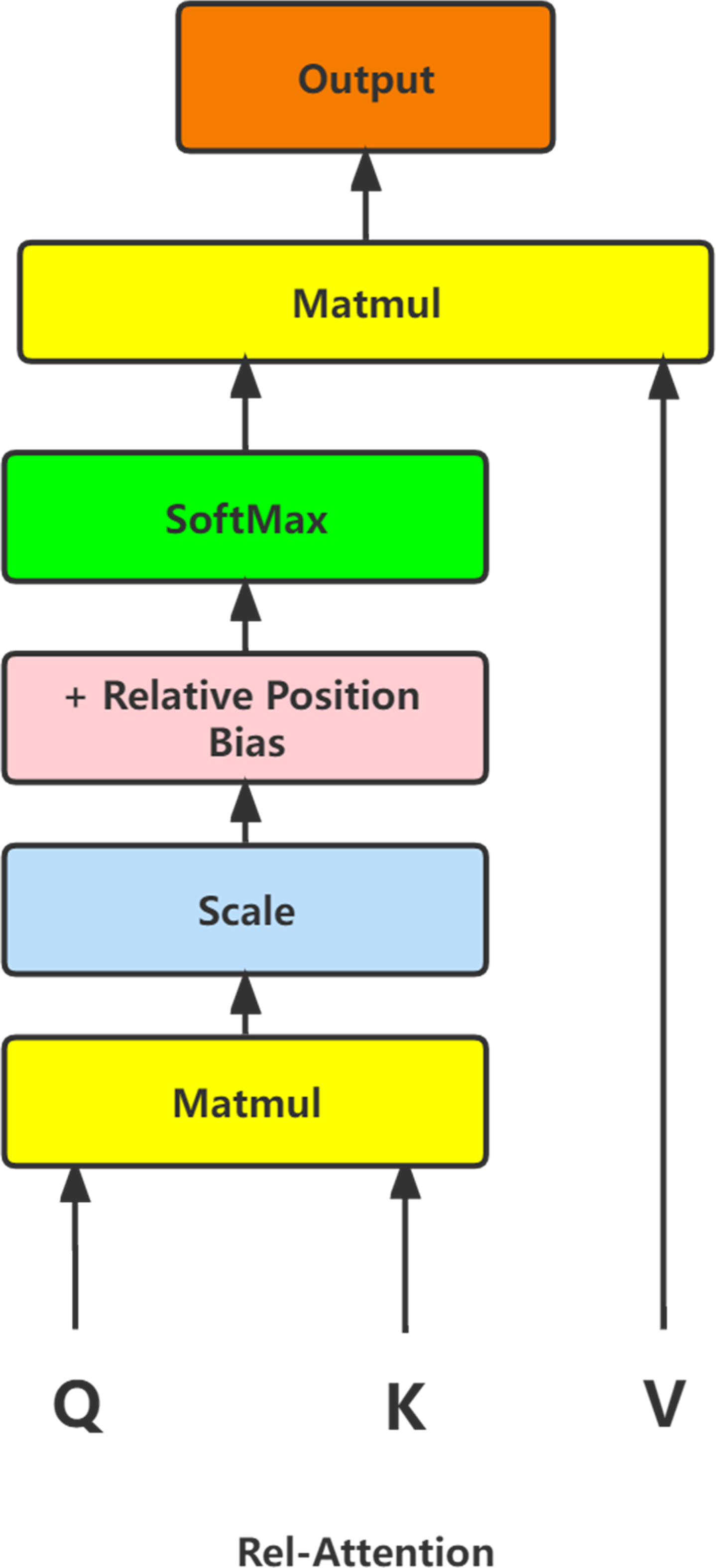
Image classification model based on large kernel attention mechanism and relative position self-attention mechanism [PeerJ]
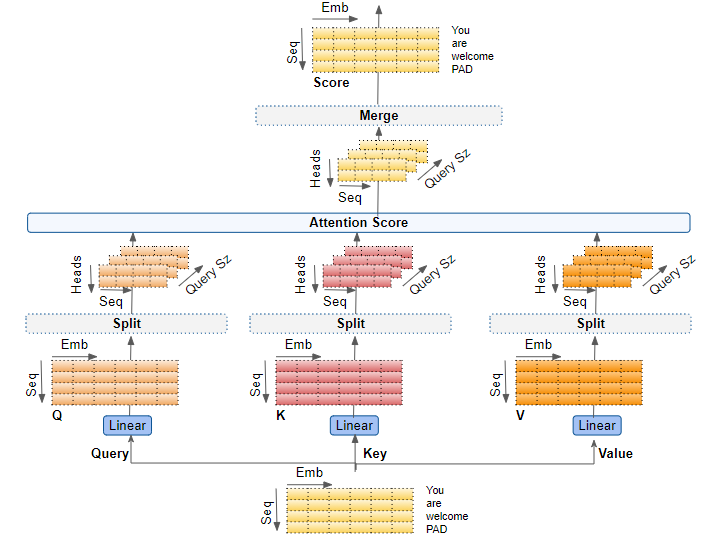
Attention
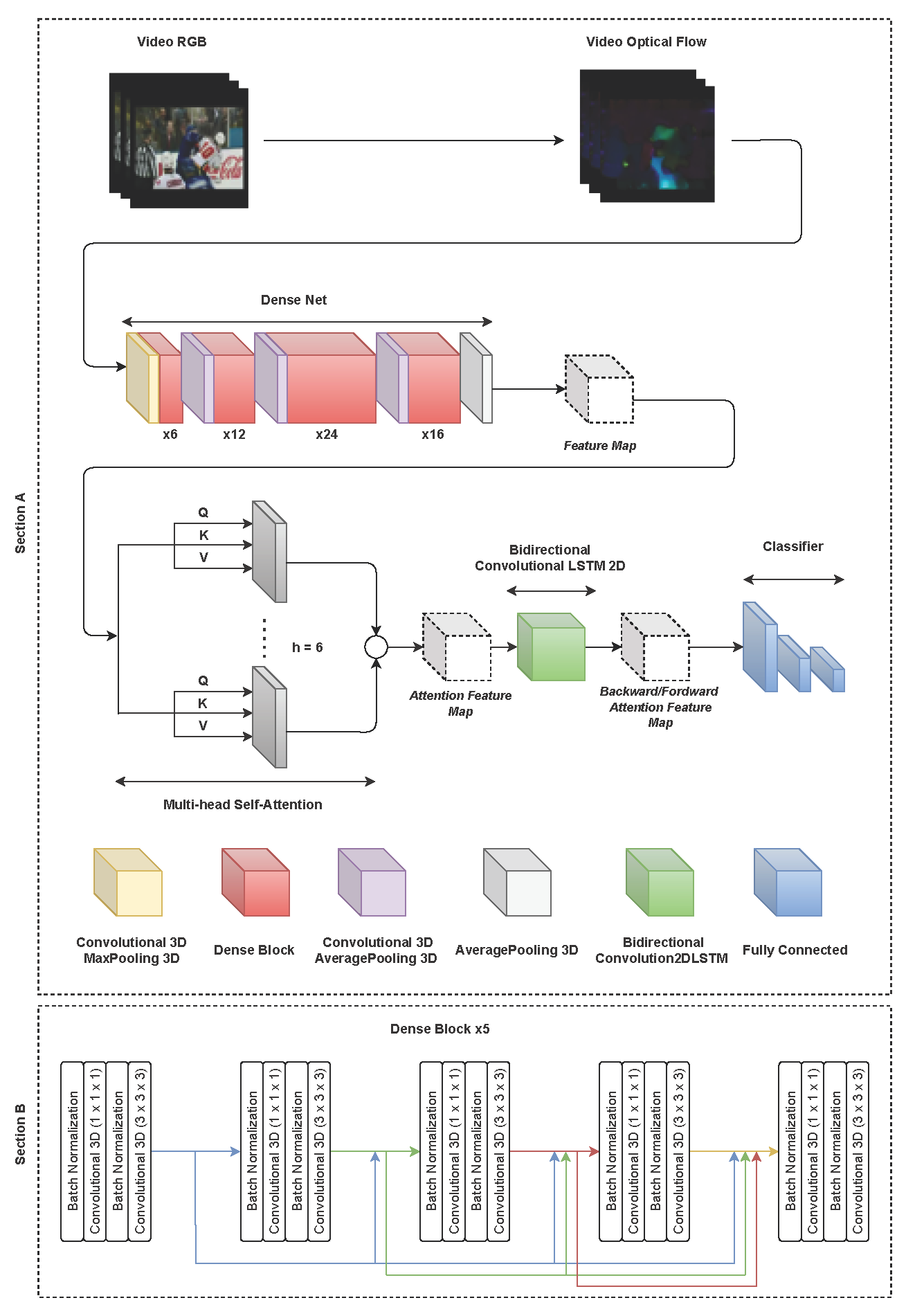
Electronics, Free Full-Text

Multi-head or Single-head? An Empirical Comparison for Transformer Training – arXiv Vanity
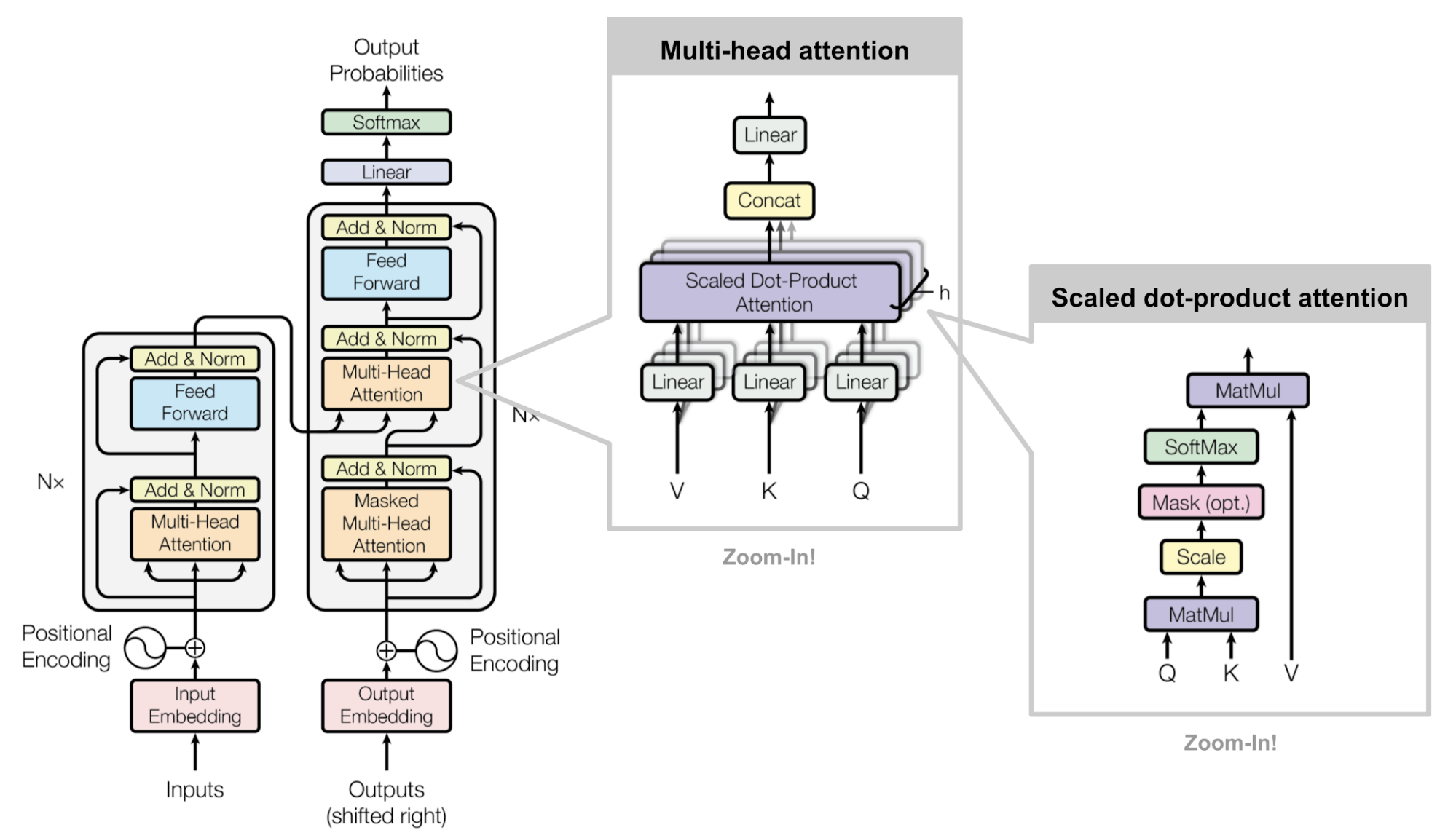
Transformers Explained Visually (Part 3): Multi-head Attention, deep dive, by Ketan Doshi
de
por adulto (o preço varia de acordo com o tamanho do grupo)