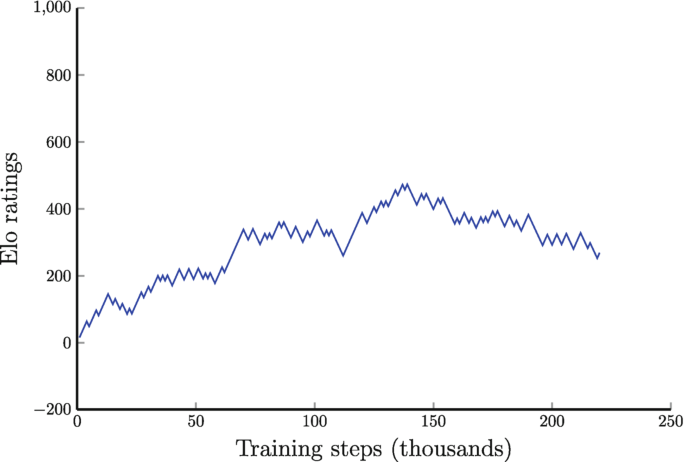
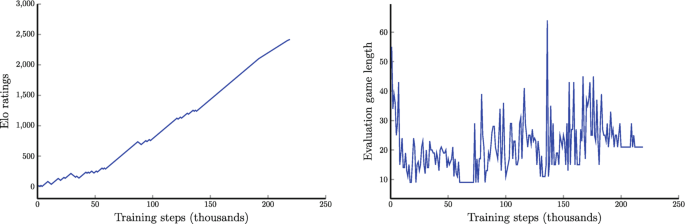
Training AlphaZero for 700,000 steps. Elo ratings were computed
Descrição
Planning with a Model: AlphaZero
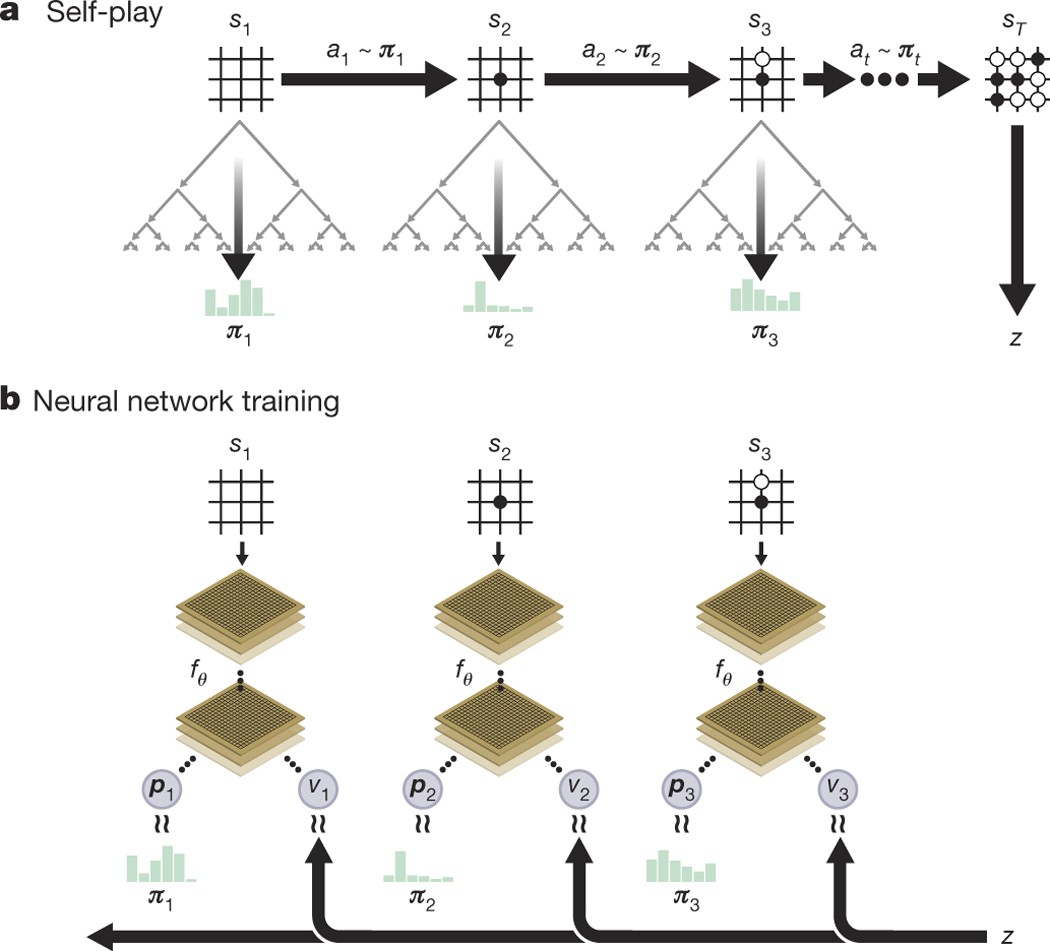
AlphaZero's pipeline. Self-play games' data are continuously generated
Planning with a Model: AlphaZero

A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play

Figure 1 from Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm

training - What does it mean for AlphaZero's network to be fully trained - Artificial Intelligence Stack Exchange

AlphaZero really is that good

Data ChessCoach

Training AlphaZero for 700,000 steps. Elo ratings were computed from

AlphaZero paper peer-reviewed is available · Issue #2069 · leela-zero/leela-zero · GitHub
How many games did Alpha Zero played against itself during its four hours training? - Quora

AlphaZero really is that good
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
de
por adulto (o preço varia de acordo com o tamanho do grupo)