Training AlphaZero for 700,000 steps. Elo ratings were computed from
Descrição

From Zero to Master in Hours: AlphaZero Accelerates Reinforcement Learning
When Alpha Zero is making seemingly bizarre moves in chess is it actually predicting what its opponent will do (calculating possibilities), or is it setting up its own attack/defense based on positional

Generally capable agents emerge from open-ended play - Google DeepMind

AlphaZero really is that good

AlphaZero really is that good

DeepMind's AlphaZero beats state-of-the-art chess and shogi game engines

Checkmate for Traditional Chess? - Nekst-Online

Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm – arXiv Vanity
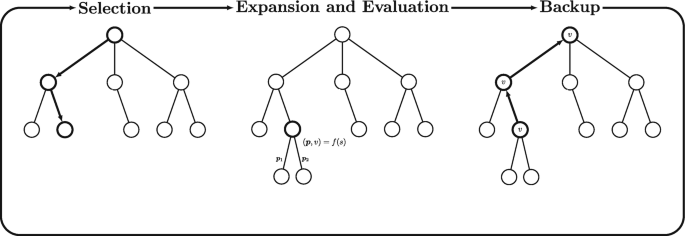
Planning with a Model: AlphaZero
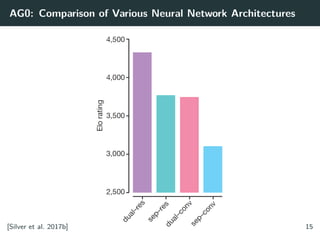
AlphaZero

Are there any ways to calculate the rating difference between AlphaGo Zero and Leela Zero? · Issue #2576 · leela-zero/leela-zero · GitHub

From Zero to Master in Hours: AlphaZero Accelerates Reinforcement Learning
de
por adulto (o preço varia de acordo com o tamanho do grupo)